We Need to Talk.
Using Conversational AI to Revolutionise your Customer Contact

Marian Wiskow
Computer Scientist at Algonaut
The advent of artificial intelligence (AI) in the natural language space is poised to revolutionize the way organizations communicate and collaborate with their customers. Instead of having people search your static website for relevant information, fill out lengthy forms, or work through hardwired dialog options of traditional chatbots, you can provide them with a truly intelligent assistant. It can link all of your organization's information with the entirety of human knowledge on the internet and provide it to the user through natural dialog. The artificial intelligence can answer each question individually and understandably based on your guidelines. This makes communication more natural, efficient and appealing to people who want to get in touch with your company. Therefore, in this article we will explain how you can succeed with a simple but effective implementation of your own AI based on OpenAI's ChatGPT.
Use Cases
There are many ways that potential customers can learn about your company. Often, your website is one of the first points of contact with customers in the digital space. It represents a good opportunity for people to explore your business. However, searching for specific information on a website, such as a specific service or technologies, can also be time-consuming and frustrating. This leads to a poor user experience and possibly the loss of leads or conversions. Now imagine if, in addition to a traditional website, your customers could interact directly with a smart partner who knows all the relevant information about your business and can relate it to the user's request. That's exactly what the implementation of conversational AI on your website is designed for.
In addition, an artificial intelligence can also take over other parts of your pitch to the customer. Depending on the context, it can give a rough overview of previous projects or explain the smallest technical aspect in detail. This gives your employees more time to focus on the most important aspects of your customer relationships. However, since artificial intelligence in the field of natural languages are fundamentally stochastic models, i.e. they work with probabilities, there are also certain risks associated with the shift to AI communication. For example, although tight limits can be placed on the outputs of a language model, they are generally never one hundred percent determinate. The relevant model parameter here is the so-called "temperature", which determines the model's degree of freedom for text generation. However, even with a temperature of 0, there are problematic tokens with non-deterministic output. Also, malicious actors could possibly cause the models to make false statements by means of so-called prompt injection attacks. However, with some precautions in place, such risks are minimal and the aforementioned advantages of an intelligent communication partner clearly outweigh the disadvantages for your customers. At least in Europe, however, an important aspect to mention is data protection regulations and the legal situation.
Legal, Security & Privacy Considerations
Defining the purpose
The obligation of purpose limitation is one of the principles of the General Data Protection Regulation (GDPR) and applies in all EU member states. Accordingly, the collection and processing of personal data may not be carried out in an unsystematic manner, but exclusively for a specific purpose. According to this principle, a purpose must be defined in order to collect personal data from the dialog system. As soon as someone uses the dialog AI, corresponding server log files and the user's full IP address are stored.
This data is collected to ensure secure and reliable operation. The server log files record attacks and malfunctions of the system and serve the purpose of recognising attack patterns and being able to trace the attacker or its provider if necessary. For tracing purposes, accesses to the server must be stored for a certain period of time, including the traceable source of the access (full IP address). As soon as this data is no longer required, it is deleted.
In order to avoid misuse of our assistant as a free interface to ChatGPT, we limit the number of daily accesses from each IP address and also collect the IP address for this reason.
Technical Requirements Architecture
The required infrastructure for a dialogue system can be kept very lean by using external APIs for text generation. To keep costs low and scalability high, we use a serverless architecture in the cloud based on Amazon Web Services (AWS). However, you can implement the system just as easily on platforms from other providers or your own server.
At the heart of an intelligent KI is the underlying language model. Recently, ChatGPT (OpenAI) placed Large Language Models (LLM) in the public limelight. In addition to a rather complex architecture, these models are characterised by a gigantic number of parameters, which are trained with the help of huge text corpora from the Internet. The training and large-scale deployment of these large models at sufficient speed has so far been the preserve of specialised companies with access the appropriate computational resources. However, the open source community is catching up at an impressive pace, such that open models will find increasing prevalence in the future. For our exemplary application, however, we want to exclude the complexity of data engineering and machine learning for the time being and therefore use an API to access externally hosted LLMs.
System Architecture
An intelligent conversational assistant can be implemented with just a few cloud services and lines of code. The following graphic provides an overview of the services used and how they interact. As already mentioned, most of these AWS services have an equivalent at other providers, so that this system architecture can also be implemented on other platforms without any problems. We will briefly discuss the functionality of the respective services.
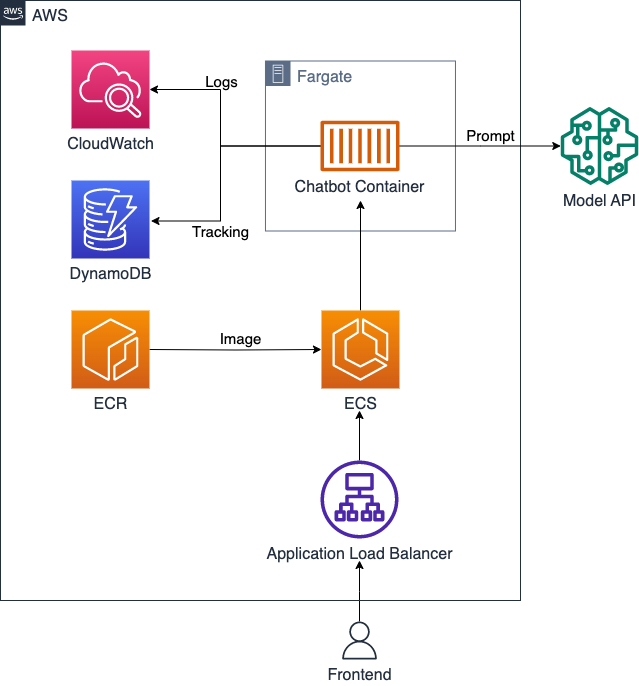
- Application Load Balancer (ALB): An ALB allows incoming network traffic to be distributed across multiple target systems, such as EC2 instances or Docker containers, to improve scalability, reliability, and availability. In our case, the load balancer also serves to maintain a static address to which the frontend can make user requests. These requests contain a user's chat message and chat history and are forwarded by the ALB to an available container for processing.
- Elastic Container Service (ECS): ECS is a managed container orchestration service. ECS allows Docker containers to be managed, orchestrated, and scaled in the AWS cloud. It enables automatic scaling based on load and integrates easily with other AWS services. ECS is responsible for keeping a certain number of containers available with our chatbot service. The number of containers is based on preset parameters within which an increased load can lead to the launch of more containers. If the load decreases, e.g. at night, ECS automatically stops containers to save resources and costs.
- Elastic Container Registry (ECR): ECR is a managed Docker image registration service. ECR provides integration with other AWS services such as Amazon ECS, which simplifies container deployment. We use ECR to deliver the application container to ECS. ECS ensures that the containers always use the latest image, making it easier to maintain on the fly.
- Fargate: Fargate is a computing service that enables container applications to run without the need to manage EC2 instances or the underlying infrastructure ("serverless"). With Fargate, containers can be easily deployed in the AWS cloud, with scaling and resource management automatically handled by AWS. This enables efficient use of compute resources while reducing the operational overhead of infrastructure management. To do this, we simply select the 'Fargate' option in ECS and set the desired compute and storage capacities. To enable ECS to manage the capacities efficiently, we only run one container per virtual compute unit at a time.
- DynamoDB: DynamoDB is a fully managed NoSQL database service. The database automatically scales and adjusts performance to meet our needs. DynamoDB supports multiple data models, provides automatic replication, security, and ACID transactions. Here we use DynamoDB to centrally store events with information about user behaviour.
- CloudWatch: CloudWatch is a monitoring and management service that enables you to monitor and analyse resources and applications in the AWS cloud. CloudWatch can collect, monitor, and analyze metrics, logs, and events to detect issues early, optimize performance, and set up automatic responses to events. We use CloudWatch to centrally track system events to ensure optimal performance and smooth operations.
The Chat-Service
The chat service represents the central technical element of dialog-oriented AI. The service accepts requests from the frontend, processes them, and sends the response back to be displayed in the UI. The service can be divided into three logical components:
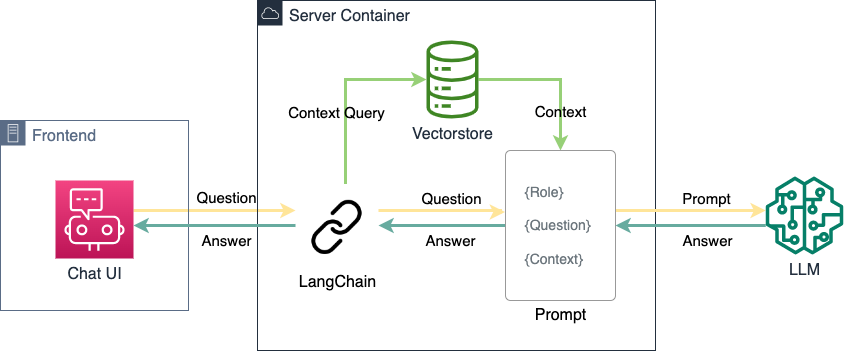
The Server
A Python server based on gunicorn accepts POST requests from the frontend and returns HTTP responses. It uses multiple worker threads to process requests asynchronously using gevent. This means that a worker process can already start processing other requests while waiting for the results of the external language model for an ongoing request, for example. Although requests to the external model API can sometimes take a few seconds, the Python server can thus process a large number of users simultaneously.
LangChain
For generating the prompts and interacting with LLMs and the knowledge database ("vectorstore"), our service uses
LangChain. Within a very short time, this Python package was able to build up a large audience because it hides different LLMs behind a common abstraction and thus enables modularity. Language models can thus be easily exchanged, concatenated or compared. We will further discuss the possibilities enabled by chaining large language models in its own chapter below.
Retrieval Augmented Generation
Lastly, the application-specific information must be provided to the selected language model. There are generally two ways to do this:
The so-called "fine-tuning" of a language model refers to the process of re-training an pretrained language model with more specific data and tasks to improve its capabilities and adapt it to a specific application or domain. Fine-tuning allows the model to develop a deeper contextualization and understanding of the specific use case. It usually involves training the model on a limited set of new data to specialise it to a particular task or specific linguistic nuances, which can lead to improved performance and accuracy. However, this process is relatively expensive, requires sufficient good quality data, and is not supported by every provider of LLMs.
However, relevant information can also be made available to the language model via a semantic store ("Retrieval Augmented Generation"; RAG). In this case, a semantically similar text document is extracted from a separate memory (usually a vectorstore) for the user query and inserted into the further prompt for the language model as context. The language model can then process this prompt as usual and use the information it contains for output. This is much more efficient and easier to implement than fine-tuning for smaller amounts of information, for example a company website. Moreover, the desired output of the language model can be more finely controlled by restricting it to the preselected context. For the purpose of a company-representative assistant, we therefore choose RAG.
Possibly the most important part of the service, however, is not necessarily of technical nature. So-called "prompt engineering" is already establishing itself as a discipline in its own right when dealing with large language models. This involves formulating the request to the language model precisely in such a way that the model performs the desired task as robustly and effectively as possible.
Model Chaining
Large language models, with their hundreds of billions of parameters and enormous text corpora, are already capable of performing a wide variety of tasks. In some cases, they are already
better than human experts on average. However, different models also have different strengths. Some LLMs can now handle image or video data. Others specialise in modelling API requests. The concatenation of models allows to develop systems that realise a majority of these strengths simultaneously. For example, a first LLM can be used to extract a task for another, specialised model from the user request. The task can be transformed into an API request by means of another LLM. After sending the request and receiving the response, it can be cast into a natural language response. Thus, the user is able to work in his own language with different APIs or AI models on the Internet. The possibilities here are already diverse, and growing in number every day. In our use case, we use model chaining to transform a message in the context of preceding messages into a standalone question that can be answered by the language model. For this, another component is essential: the prompt.
Prompt Engineering
As in many other technical disciplines, an iterative process is a good starting point in prompt engineering. So we start with a simple input, and improve it over several steps to finally come up with a robust and concise prompt tailored to our application.
Q&A Prompt
At the beginning of our journey, we focused on a very simple prompt. The first part simply embeds the user's question. In the second part, the language model is assigned the role of friendly and professional assistant in which it should formulate the answer:
TEMPLATE_PLAIN = """
Question: {question}
Answer: I am always friendly and professional and happy to help you.
"""
Taking a role is one of the most powerful capabilities of large language models. It not only determines the form and tone of the output, but also activates associated knowledge that is drawn upon for the response. You should know your target group well in order to be able to generate an appropriate address via prompt engineering. The model can thus act as anything from a childish, playful companion to a neurotic expert in paleoarchaeology, in order to provide the unique user experience you wish for your users.
Retrieval Augmented Generation (RAG) Prompt
In the next iteration, we move from the simpler Q&A scenario to the RAG scenario. In this prompt, the model is again sworn in to its role as an AI assistant. This has been supplemented with further rules for e.g. output length, referencing web pages and avoiding repetition. In order to map the knowledge extracted from the vector store, the extracted text passage is also inserted into this prompt as context and marked. It must be ensured that the length of the prompt including the context does not exceed the maximum input length (measured in token count) of the language model used. This can be ensured by selecting a sufficiently small "chunk size" when setting up the vector store. Newer models also usually allow larger inputs, so that more context can be passed.
TEMPLATE_QA = """
You are a friendly and professional AI assistant who likes to talk to the user.
You represent the company Algonaut, and try to help the user get to know the company.
If necessary, use the following contextual information to answer the question at the end.
Try not to repeat yourself too much, and use your own words and knowledge to give a good answer.
Try to keep it short. In your answer, do not refer to websites that are not located at 'www.algonaut.com'.
If you do not know an answer, you can ask to use the contact form to get more information.
Context: {context}
Question: {question}
Answer:
"""
RAG prompt with source references
The above prompt can also be extended with the instruction to specify the source of the context piece. Since we use a vectorstore for context extraction, we can name the source exactly. This can alleviate the problem of "hallucinations" that large language models often suffer from. This can increase user confidence in the output of your AI, as they can independently evaluate the source of the answer. Use cases for this would include scientific questions or conversations with large documents such as the IPCC climate report, which can be hundreds of pages long.
TEMPLATE_QA_SOURCES = """
Use the following parts of a long document to answer the question at the end with reference to the sources ("SOURCES").
If you do not know the answer, say so and do not make up an answer.
If you don't know the answer, ask to use the contact form to get more information.
You are always friendly and professional when doing so.
{summaries}
Question: {question}
Answer:
"""
Dialog-oriented prompt
For our example, however, a prompt with a focus on the conversation is best suited. In addition to the message, the message history is also added to this, so that the model can respond to previous interactions. This allows a dialog-oriented interaction to some extent even with models that have not been specifically adapted for it.
TEMPLATE_QA_CONVERSATIONAL = """
The user of a chatbot has written a message.
If the message is self-contained and interpretable without further context, output it unchanged.
If the message is not self-contained, use the previous conversation flow to rephrase
the message as an independent question.
Message: {question}
Conversation history: {chat_history}
Self-contained question:
"""
It is important to note that the prompts considered above are merely examples to illustrate certain aspects of prompt engineering. In fact, good prompts are often much more complex and extensive. This is where it pays to invest time in multiple iterations, as the prompt is central to the performance of your conversational AI.
What's next?
As mentioned above, the present application example by no means exhausts the diverse capabilities of modern language models. Model chaining can create systems with a wide range of capabilities. Examples include natural language integration of external APIs, interaction with audio-visual media, or enhanced mathematical capabilities. By chaining more interfaces or models, LLMs can make their information and products available to a larger set of people through a natural mode of interaction. As we have seen, this integration can be implemented quickly and effectively with modern tools.
Dialog-oriented interactions will significantly shape the Internet in the future. Instead of merely consuming static and structured information, we will increasingly be able to communicate with computers and online services in natural language. This will be made possible by rapid advances in artificial intelligence and language processing. Dialogue systems such as voice assistants and chatbots are becoming increasingly intelligent and can answer complex questions, solve problems and even provide emotional support. They will be able to provide personalised recommendations, understand individual needs, and offer tailored services. These conversational interactions will make the Internet an even more intuitive, efficient, and user-friendly medium that supports us in a wide range of areas of daily life, be it shopping, customer service, education, or entertainment. The future of the Internet will be characterised by this type of interactive communication, which will open up new possibilities and fundamentally change our relationship with the digital world. Thus, people will not only consume information, but interact with it directly.
If you need further expertise to implement conversational AI for your company, start a conversation with our intelligent assistant today!

