Wir müssen reden.
Wie Sie mit dialogorientierter KI Ihren Kundenkontakt revolutionieren

Marian Wiskow
Computer Scientist at Algonaut
Das Aufkommen der Künstlichen Intelligenz (KI) im Bereich der natürlichen Sprache ist im Begriff die Art und Weise zu revolutionieren, wie Organisationen mit ihren Kunden kommunizieren und zusammenarbeiten. Anstatt Menschen Ihre statische Webseite nach relevanten Informationen durchsuchen, langwierige Formulare ausfüllen, oder festverdrahtete Dialogoptionen von klassischen Chatbots durchexerzieren zu lassen, können Sie ihnen einen intelligenten Assistenten zur Seite stellen. Dieser kann alle Informationen ihrer Organisation mit dem Wissen des Internets verknüpfen und jedem Nutzer im Dialog näher bringen. Die künstliche Intelligenz kann jede Frage basierend auf ihren Vorgaben individuell und verständlich beantworten. Die Kommunikation wird dadurch natürlicher, effizienter und ansprechender für Menschen, die mit Ihrem Unternehmen in Kontakt treten möchten. Deshalb erklären wir in diesem Artikel, wie eine einfache aber effektive Implementation einer eigenen KI basierend auf ChatGPT von OpenAI gelingen kann.
Anwendungsfälle
Es gibt viele Möglichkeiten, wie potentielle Kunden von Ihrem Unternehmen erfahren können. Die firmeneigene Webseite stellt im digitalen Raum einen der ersten Kontaktpunkte mit Ihrem Unternehmen dar. Sie stellt eine gute Möglichkeit dar, sich explorativ mit dem Unternehmen auseinander zu setzen um einen ersten Eindruck zu bekommen. Die Suche nach bestimmten Informationen auf einer Webseite, etwa zu einer speziellen Dienstleistung oder Technologien, kann jedoch auch zeitintensiv und frustrierend sein. Das führt zu einer schlechten Nutzererfahrung und womöglich dem Verlust von Leads oder Conversions. Stellen Sie sich nun vor, zusätzlich zu einer traditionellen Webseite könnten Ihre Kunden direkt mit einem intelligenten Partner interagieren, der alle relevanten Informationen über Ihr Unternehmen kennt. Genau das ermöglicht die Implementierung einer dialogorientierten KI auf Ihrer Webseite.
Darüberhinaus kann eine künstliche Intelligenz auch weitere Teile eines Kundengesprächs übernehmen. Sie kann sowohl einen groben Überblick über bisherige Projekte geben als auch das kleinste technische Detail ausführlich erklären. Ihre Mitarbeitenden bekommen dadurch mehr Zeit, um sich auf die wichtigsten, nämlich die sozialen, Aspekte Ihrer Kundenkontakte zu konzentrieren. Da künstliche Intelligenzen im Bereich der natürlichen Sprachen grundsätzlich stochastische Modelle sind, also mit Wahrscheinlichkeiten arbeiten, sind jedoch auch gewisse Risiken mit der Verlagerung hin zur KI-Kommunikation verbunden. So lassen sich den Ausgaben eines Sprachmodells zwar enge Grenzen setzen, jedoch sind sie in der Regel niemals zu einhundert Prozent determiniert. Der relevante Modell-Parameter ist hier die sog. “temperature”, welche den Freiheitsgrad der Textgenerierung bestimmt. Jedoch gibt es selbst bei einer temperature von 0 problematische Tokens mit nichtdeterministischem Output. Auch könnten bösartige Akteure die Modelle mittels sogenannten prompt injection Angriffen unter Umständen dazu bringen, Falschaussagen zu machen. Mit den richtigen Mitteln sind derlei Risiken jedoch beherrschbar, sodass die genannten Vorteile eines intelligenten Kommunikationspartners für ihre Kunden klar überwiegen. Ein wichtiger Aspekt stellen dabei die Datenschutzbestimmungen und die Rechtslage dar.
Datenschutzaspekte
Zweckdefinition
Die Pflicht zur Zweckbindung ist einer der Grundsätze der Datenschutz-Grundverordnung (DSGVO) und gilt in allen EU-Mitgliedstaaten. Grundlage für die Datenverarbeitung ist Art. 6 Abs. 1 lit. f DSGVO, der die Verarbeitung von Daten aufgrund berechtigten Interesses gestattet: Die Erhebung und Verarbeitung personenbezogener Daten darf demnach nicht unsystematisch, sondern ausschließlich zweckgebunden erfolgen. Gemäß diesem Grundsatz muss für die Erfassung der personenbezogenen Daten des Dialogsystems ein Zweck definiert werden. Sobald jemand die Dialog-KI verwendet, werden entsprechende Server-Logfiles sowie die vollständige IP-Adresse des Nutzers gespeichert.
Diese Daten werden erfasst, um einen sicheren und zuverlässigen Betrieb sicherzustellen. Die Server-Logfiles erfassen Angriffe und Fehlfunktionen des Systems und dienen dem Zweck, Angriffsmuster zu erkennen und den Angreifer bzw. dessen Provider ggf. rückverfolgen zu können. Für die Rückverfolgung müssen Zugriffe auf den Server für eine gewisse Dauer unter Einschluss der rückverfolgbaren Quelle des Zugriffs (vollständige IP-Adresse) gespeichert werden. Sobald diese Daten nicht mehr benötigt werden, werden sie gelöscht. Um eine missbräuchliche Verwendung des kostenfreien ChatGPT-Frontends zu vermeiden, begrenzen wir die Zahl der täglichen Zugriffe von jeder einzelnen IP-Adresse und erheben auch aus diesem Grund die IP-Adresse.
Technische Voraussetzungen
Die benötigte Infrastruktur für einen Chatbot kann durch die Verwendung von externen APIs zur Textgenerierung sehr schlank gehalten werden. Um Kosten gering und die Skalierbarkeit hoch zu halten, nutzen wir eine serverless-Architektur in der Cloud basierend auf Amazon Web Services (AWS). Sie können den Chatbot aber ebenso problemlos auf Plattformen anderer Anbieter oder ihrem eigenen Server implementieren.
Das Herzstück eines intelligenten Chatbots ist das zugrundeliegende Sprachmodell. Mit ChatGPT (OpenAI) sind Large Language Models (dt. große Sprachmodelle; LLM) erstmals auch außerhalb der Fachkreise in das Scheinwerferlicht gerückt. Diese Modelle zeichnen sich neben einer komplexen Architektur durch eine gigantische Zahl an Parametern aus, welche mithilfe von riesigen Textkorpora aus dem Internet trainiert werden. Das Training und die hochskalierte Bereitstellung dieser großen Modelle ist in hinreichender Geschwindigkeit bislang spezialisierten Unternehmen mit entsprechenden Ressourcen vorbehalten. Jedoch schließt die Open Source Community in beeindruckendem Tempo auf, sodass in Zukunft auch offene Modelle vermehrt Einsatz finden werden. Für unsere Beispielanwendung wollen wir jedoch vorerst die Komplexität des Data Engineering und Machine Learning ausklammern und verwenden deshalb eine API, um extern gehostete LLMs anzusprechen.
Systemarchitektur
Ein intelligenter Ansprechpartner lässt sich bereits mit wenigen Cloud-Services und Codezeilen umsetzen. Die folgende Grafik gibt einen Überblick über die verwendeten Services und ihr Zusammenspiel. Wie bereits erwähnt haben die meisten dieser AWS-Dienste ein äquivalent bei anderen Anbietern, sodass sich diese Systemarchitektur problemlos auch auf anderen Plattformen umsetzen lässt. Wir gehen dazu kurz auf die Funktionalität der jeweiligen Services ein.
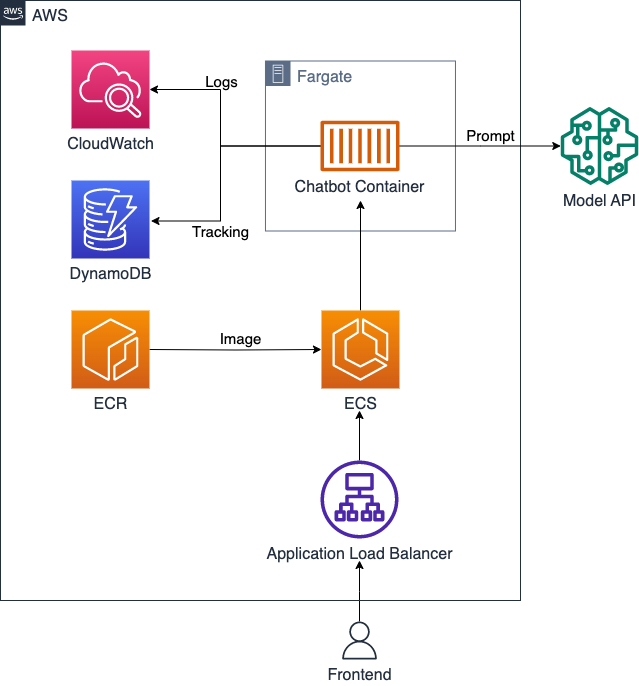
- Application Load Balancer (ALB): Ein ALB ermöglicht die Verteilung des eingehenden Netzwerkverkehrs auf mehrere Zielsysteme, wie z.B. EC2-Instanzen oder Docker Container, um die Skalierbarkeit, Zuverlässigkeit und Verfügbarkeit zu verbessern. In unserem Fall dient der Load Balancer zudem dazu, eine statische Adresse zu erhalten, woran das Frontend Benutzeranfragen stellen kann. Diese Anfragen enthalten die Chatnachricht eines Nutzers sowie den Chatverlauf und werden vom ALB an einen verfügbaren Container zur Bearbeitung weitergeleitet.
- Elastic Container Service (ECS): ECS ist ein verwalteter Container-Orchestrierungsdienst. Mit ECS können Docker-Container in der AWS-Cloud verwaltet, orchestriert und skaliert werden. Es ermöglicht automatisches Skalieren basierend auf der Last und integriert sich leicht mit anderen AWS-Services. ECS ist dafür verantwortlich, eine gewisse Zahl an Containern mit unserem Chatbot-Service verfügbar zu halten. Die Anzahl an Containern orientiert sich dabei an voreingestellten Parametern, innerhalb derer eine erhöhte Last zum Start weiterer Container führen kann. Geht die Last etwa Nachts zurück, so stoppt ECS automatisch Container um so Ressourcen und Kosten zu sparen.
- Elastic Container Registry (ECR): ECR ist ein verwalteter Docker-Image-Registrierungsdienst. ECR bietet eine Integration mit anderen AWS-Services wie Amazon ECS, was die Containerbereitstellung vereinfacht. Wir verwenden ECR, um den Chatbot-Container an ECS auszuliefern. ECS sorgt dafür, dass die Container immer das neueste Image verwenden, und erleichtert so die Wartung im laufenden Betrieb.
- Fargate: Fargate ist ein Computing-Dienst, der es ermöglicht, Containeranwendungen auszuführen ohne die Notwendigkeit, EC2-Instanzen oder die zugrunde liegende Infrastruktur zu verwalten (”serverless”). Mit Fargate können Container einfach in der AWS-Cloud bereitgestellt werden, wobei die Skalierung und Ressourcenverwaltung automatisch von AWS übernommen wird. Dies ermöglicht eine effiziente Nutzung von Compute-Ressourcen und reduziert gleichzeitig den operativen Aufwand für die Infrastrukturverwaltung. Dafür wählen wir in ECS lediglich die ‘Fargate’-Option und stellen die gewünschten Rechen- und Speicherkapazitäten ein. Um ECS eine effiziente Verwaltung der Kapazitäten zu ermöglichen, lassen wir dabei jeweils nur einen Container pro virtueller Recheneinheit laufen.
- DynamoDB: DynamoDB ist ein vollständig verwalteter NoSQL-Datenbankdienst. Die Datenbank skaliert automatisch und passt die Leistung an unsere Bedürfnisse an. DynamoDB unterstützt mehrere Datenmodelle, bietet automatische Replikation, Sicherheit und ACID-Transaktionen. Hier verwenden wir DynamoDB, um Ereignisse mit Informationen über das Benutzerverhalten zentral zu speichern.
- CloudWatch: CloudWatch ist ein Überwachungs- und Verwaltungsdienst, mit dem Sie Ressourcen und Anwendungen in der AWS-Cloud überwachen und analysieren können. CloudWatch kann Metriken, Protokolle und Ereignisse sammeln, überwachen und analysieren, um Probleme frühzeitig zu erkennen, die Leistung zu optimieren und automatische Reaktionen auf Ereignisse einzurichten. Wir verwenden CloudWatch zur zentralen Verfolgung von Systemereignissen, um eine optimale Leistung und einen reibungslosen Betrieb zu gewährleisten.
Der Chat-Service
Der Chat-Service stellt das zentrale technische Element der dialogorientierten KI dar. Der Service nimmt Anfragen vom Frontend an, bearbeitet diese, und schickt die fertige Antwort der KI zurück um in der UI angezeigt zu werden. Der Service lässt sich dabei in drei logische Komponenten einteilen.
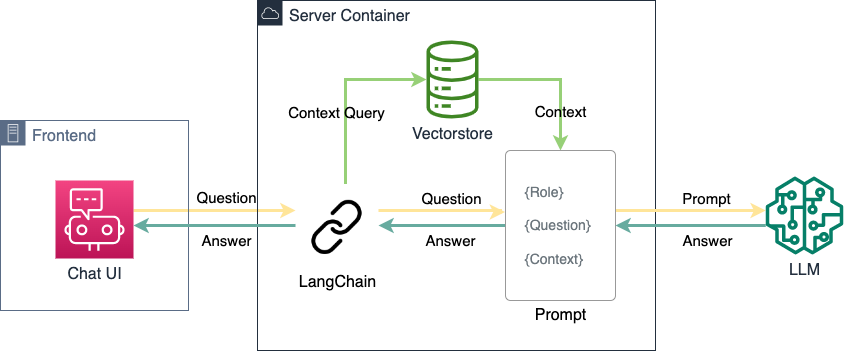
Der Server
Ein Python-Server, basierend auf gunicorn, nimmt POST-Requests des Frontends entgegen und gibt HTTP Responses zurück. Er verwendet mehrere Worker-Threads, um mittels gevent Anfragen asynchron zu verarbeiten. Dies bedeutet, dass ein Worker-Prozess bereits mit der Bearbeitung von anderen Anfragen beginnen kann, während er für eine laufende Anfrage beispielsweise auf die Ergebnisse des externen Sprachmodells wartet. Obwohl die Anfragen an die externe Modell-API mitunter einige Sekunden dauern können, kann der Python-Server somit eine Vielzahl an Nutzenden gleichzeitig verarbeiten.
LangChain
Für das Erzeugen der Prompts und die Interaktion mit LLMs und dem Vectorstore verwendet unser Service
LangChain. Innerhalb kürzester Zeit konnte dieses Python Package ein großes Publikum aufgebauen, da es verschiedene LLMs hinter einer gemeinsamen Abstraktion verbirgt und damit eine Modularität ermöglicht. Sprachmodelle können somit leicht ausgetauscht, verkettet oder verglichen werden. Auf die Möglichkeiten durch Verkettung großer Sprachmodelle gehen wir in einem gesonderten Kapitel weiter ein.
Retrieval Augmented Generation
Zuletzt müssen dem gewählten Sprachmodell die anwendungsspezifischen Informationen zur Verfügung gestellt werden. Zu diesem Zweck gibt es im Wesentlichen zwei Möglichkeiten:
Das sogenannte “Fine-Tuning” eines Sprachmodells bezieht sich auf den Prozess, bei dem ein bereits trainiertes Sprachmodell nochmals mit spezifischeren Daten und Aufgaben trainiert wird, um seine Fähigkeiten zu verbessern und an eine bestimmte Anwendung oder Domäne anzupassen. Durch das Feinabstimmen kann das Modell eine tiefere Kontextualisierung und ein besseres Verständnis für den spezifischen Anwendungsfall entwickeln. Es beinhaltet normalerweise das Trainieren des Modells auf einem begrenzten Satz von neuen Daten, um es auf eine bestimmte Aufgabe oder spezifische sprachliche Nuancen zu spezialisieren, was zu einer verbesserten Leistung und Genauigkeit führen kann. Dieser Prozess ist jedoch vergleichsweise aufwendig, benötigt ausreichend Daten in guter Qualität, und wird nicht von jedem Anbieter unterstützt.
Relevante Informationen können dem Sprachmodell jedoch auch über einen semantischen Speicher verfügbar gemacht werden (”Retrieval Augmented Generation”; RAG). Dabei wird zur Nutzeranfrage ein semantisch ähnliches Textdokument aus einem separaten Speicher (”vectorstore”) extrahiert und in den weiteren Prompt für das Sprachmodell als Kontext eingesetzt. Das Sprachmodell kann diesen Prompt dann wie üblich verarbeiten und die darin enthaltenen Informationen für die Ausgabe nutzen. Dieser Weg ist für kleinere Informationsmengen, beispielsweise eine Firmen-Webseite, deutlich effizienter und einfacher umzusetzen als Fine-Tuning. Zudem kann die gewünschte Ausgabe des Sprachmodells durch eine Restriktion auf den vorausgewählten Kontextes feiner kontrolliert werden. Für den Zweck unseres firmenrepräsentativen Assistenten entscheiden wir uns deshalb für RAG.
Der womöglich wichtigste Teil des Services ist jedoch nicht unbedingt technischer Natur. Das sogenannte “Prompt Engineering” ist bereits im Begriff, sich als eigenständige Disziplin im Umgang mit großen Sprachmodellen zu etablieren. Hierbei geht es darum, die Anfrage an das Sprachmodell präzise so zu formulieren, dass das Modell die gewünschte Aufgabe möglichst robust und effektiv erfüllt.
Model Chaining
Große Sprachmodelle sind mit ihren Hunderten von Milliarden Parametern und enormen Textkorpora bereits in der Lage eine Vielzahl an unterschiedlichsten Aufgaben zu erledigen. Teilweise sind sie dabei im Durchschnitt bereits
besser als menschliche Expertinnen und Experten. Jedoch haben unterschiedliche Modelle auch unterschiedliche Stärken. So können die meisten LLMs z.B. nicht mit Bild- oder Videodaten umgehen. Andere sind darauf spezialisiert, API-Anfragen zu modellieren. Die Verkettung von Modellen erlaubt es, Systeme zu entwickeln welche eine Mehrzahl dieser Stärken gleichzeitig realisiert. Beispielsweise kann ein erstes LLM verwendet werden, um aus der Nutzeranfrage eine Aufgabe für ein weiteres, spezialisiertes Modell zu extrahieren. Diese kann mittels eines weiteren LLMs z.B. in eine API-Anfrage umgewandelt werden. Nach Versenden der Anfrage und Erhalten der Antwort kann diese mit einem weiteren LLM in eine natürlichsprachliche Antwort gegossen werden. Somit ist der Nutzende in der Lage, in seiner eigenen Sprache mit verschiedenen APIs oder KI-Modellen im Internet zu arbeiten. Die Möglichkeiten sind hier bereits jetzt vielfältig, und werden jeden Tag zahlreicher. In unserem Anwendungsfall verwenden wir Model Chaining, um eine Nachricht im Kontext vorangehender Nachrichten in eine alleinstehende Frage umzuwandeln, welche von dem Sprachmodell beantwortet werden kann. Hierzu ist eine weitere Komponente essentiell: das Prompt.
Prompt Engineering
Wie in vielen anderen technischen Disziplinen, so ist auch im Prompt Engineering ein iterativer Prozess ein guter Ansatzpunkt. So beginnen wir mit einer einfachen Eingabe, und verbessern sie über mehrere Schritte hinweg um schlussendlich ein auf unsere Anwendung individuell zugeschnittenes, robustes und konzises Prompt zu erarbeiten.
Q&A Prompt
Zu Beginn unserer Reise haben wir auf ein sehr simples Prompt gesetzt. Im ersten Teil wird lediglich die Frage des Nutzenden eingebettet. Im zweiten Teil wird dem Sprachmodell die Rolle des freundlichen und professionellen Assistenten zugewiesen, in welcher es die Antwort formulieren soll:
TEMPLATE_PLAIN = """
Question: {question}
Answer: I am always friendly and professional and happy to help you.
"""
Das Einnehmen einer Rolle ist eine der mächtigsten Fähigkeiten von großen Sprachmodellen. Sie bestimmt nicht nur Form und Tonalität der Ausgabe, sondern aktiviert auch assoziiertes Wissen, auf welches für die Antwort zurückgegriffen wird. Hier verwenden wir zum Beispiel ‘Ihnen’, um das Modell implizit aufzufordern, unsere Nutzer zu Siezen. Sie sollten Ihre Zielgruppe gut kennen, um via Prompt Engineering eine geeignete Ansprache erzeugen zu können. Das Modell kann so jede Rolle einnehmen, vom kindlichen, spielerischen Begleiter bis hin zum neurotischen Experten für Paläoarchäologie.
Retrieval Augmented Generation (RAG) Prompt
In der nächsten Iteration gehen wir von dem einfacheren Q&A-Szenario in das RAG-Szenario über. In diesem Prompt wird das Modell erneut auf seine Rolle als KI-Assistent eingeschworen. Dies wurde ergänzt durch weitere Regeln für bspw. die Länge der Ausgabe, das Verweisen auf Webseiten und das Vermeiden von Wiederholungen. Um das aus dem Vectorstore extrahierte Wissen abzubilden, wird diesem Prompt zudem die extrahierte Textstelle als Kontext eingefügt und gekennzeichnet. Hierbei muss sichergestellt werden, dass die Länge des Prompts inklusive des Kontexts die maximale Eingabelänge (gemessen in Tokenanzahl) des verwendeten Sprachmodells nicht übersteigen darf. Dies kann durch eine ausreichend klein gewählte “chunk size” beim Aufsetzen des Vectorstores sichergestellt werden. Neuere Modelle erlauben zudem meist größere Eingaben, sodass mehr Kontext übergeben werden kann.
TEMPLATE_QA = """
You are a friendly and professional AI assistant who likes to talk to the user.
You represent the company Algonaut, and try to help the user get to know the company.
If necessary, use the following contextual information to answer the question at the end.
Try not to repeat yourself too much, and use your own words and knowledge to give a good answer.
Try to keep it short. In your answer, do not refer to websites that are not located at 'www.algonaut.com'.
If you do not know an answer, you can ask to use the contact form to get more information.
Context: {context}
Question: {question}
Answer:
"""
RAG Prompt mit Quellverweisen
Das obige Prompt kann zudem um die Anweisung erweitert werden, die Quelle des Kontextstücks anzugeben. Da wir für die Kontextextraktion einen Vectorstore verwenden, können wir die Quelle exakt benennen. Dies vermeidet das Problem von “Halluzinationen”, worunter große Sprachmodelle oft leiden. Das kann das Vertrauen der Nutzenden in die Ausgabe Ihrer KI stärken, da sie die Quelle der Antwort unabhängig bewerten können. Anwendungsbeispiele hierzu wären etwa wissenschaftliche Fragestellungen oder Konversationen mit großen Dokumenten wie etwa dem mehrere tausend Seiten umfassenden IPCC-Klimabericht.
TEMPLATE_QA_SOURCES = """
Use the following parts of a long document to answer the question at the end with reference to the sources ("SOURCES").
If you do not know the answer, say so and do not make up an answer.
If you don't know the answer, ask to use the contact form to get more information.
You are always friendly and professional when doing so.
{summaries}
Question: {question}
Answer:
"""
Dialogorientiertes Prompt
Für unser Beispiel ist jedoch ein Prompt mit Fokus auf die Konversation am Besten geeignet. Diesem wird zusätzlich zur Nachricht auch der Nachrichtenverlauf eingefügt, sodass das Modell auf vorangegangene Interaktionen eingehen kann. Dies ermöglicht eine dialogorientierte Interaktion zu einem gewissen Grad sogar mit Modellen, die nicht spezifisch darauf angepasst wurden.
TEMPLATE_QA_CONVERSATIONAL = """
The user of a chatbot has written a message.
If the message is self-contained and interpretable without further context, output it unchanged.
If the message is not self-contained, use the previous conversation flow to rephrase
the message as an independent question.
Message: {question}
Conversation history: {chat_history}
Self-contained question:
"""
Es ist wichtig zu erwähnen, dass die oben betrachteten Prompts lediglich Beispiele für die Verdeutlichung gewisser Aspekte des Prompt Engineering darstellen. Tatsächlich sind gute Prompts oft wesentlich komplexer und umfangreicher. Hier lohnt es sich, Zeit in mehrere Iterationen zu investieren, da das Prompt für die Performance Ihrer dialogorientierten KI von zentraler Bedeutung ist.
Wie gehts es weiter?
Wie oben bereits erwähnt, schöpft das vorliegende Anwendungsbeispiel keinesfalls die vielfältigen Fähigkeiten moderner Sprachmodelle aus. Durch Model Chaining können Systeme mit einem breiten Spektrum an Funktionen schaffen. Beispiele sind etwa die natürlichsprachliche Integration von externen APIs, Interaktion mit audiovisuellen Medien oder verbesserte mathematische Fähigkeiten. Durch das Anbinden weiterer Schnittstellen oder Modelle können LLMs ihre Informationen und Produkte einer größeren Menge an Menschen durch eine natürliche Interaktion zur Verfügung stellen. Wie wir gesehen haben ist diese Integration mit modernen Werkzeugen dabei schnell und effektiv umzusetzen.
Dialogorientierte Interaktionen werden das Internet in Zukunft maßgeblich prägen. Anstatt lediglich statische und strukturierte Informationen zu konsumieren, werden wir vermehrt in der Lage sein, mit Computern und Online-Diensten in natürlicher Sprache zu kommunizieren. Dies wird durch die zügigen Fortschritte im Bereich der Künstlichen Intelligenz und der Sprachverarbeitung ermöglicht. Dialogsysteme wie Sprachassistenten und Chatbots werden immer intelligenter und können komplexe Fragen beantworten, Probleme lösen und sogar emotionale Unterstützung bieten. Sie werden in der Lage sein, personalisierte Empfehlungen zu geben, individuelle Bedürfnisse zu verstehen und maßgeschneiderte Dienstleistungen anzubieten. Durch diese dialogorientierten Interaktionen wird das Internet zu einem noch intuitiveren, effizienteren und benutzerfreundlicheren Medium, das uns in vielfältigen Bereichen des täglichen Lebens unterstützt, sei es beim Einkaufen, der Kundenbetreuung, der Bildung oder der Unterhaltung. Die Zukunft des Internets wird von dieser Art der interaktiven Kommunikation geprägt sein, die uns neue Möglichkeiten eröffnet und unsere Beziehung zur digitalen Welt grundlegend verändert. So werden Menschen nicht nur Informationen konsumieren, sondern direkt mit ihnen interagieren.
Falls Sie für die Umsetzung einer dialogorienterten KI für Ihr Unternehmen weitere Expertise benötigen, starten Sie doch einfach ein Gespräch mit unserem intelligenten Assistenten!

